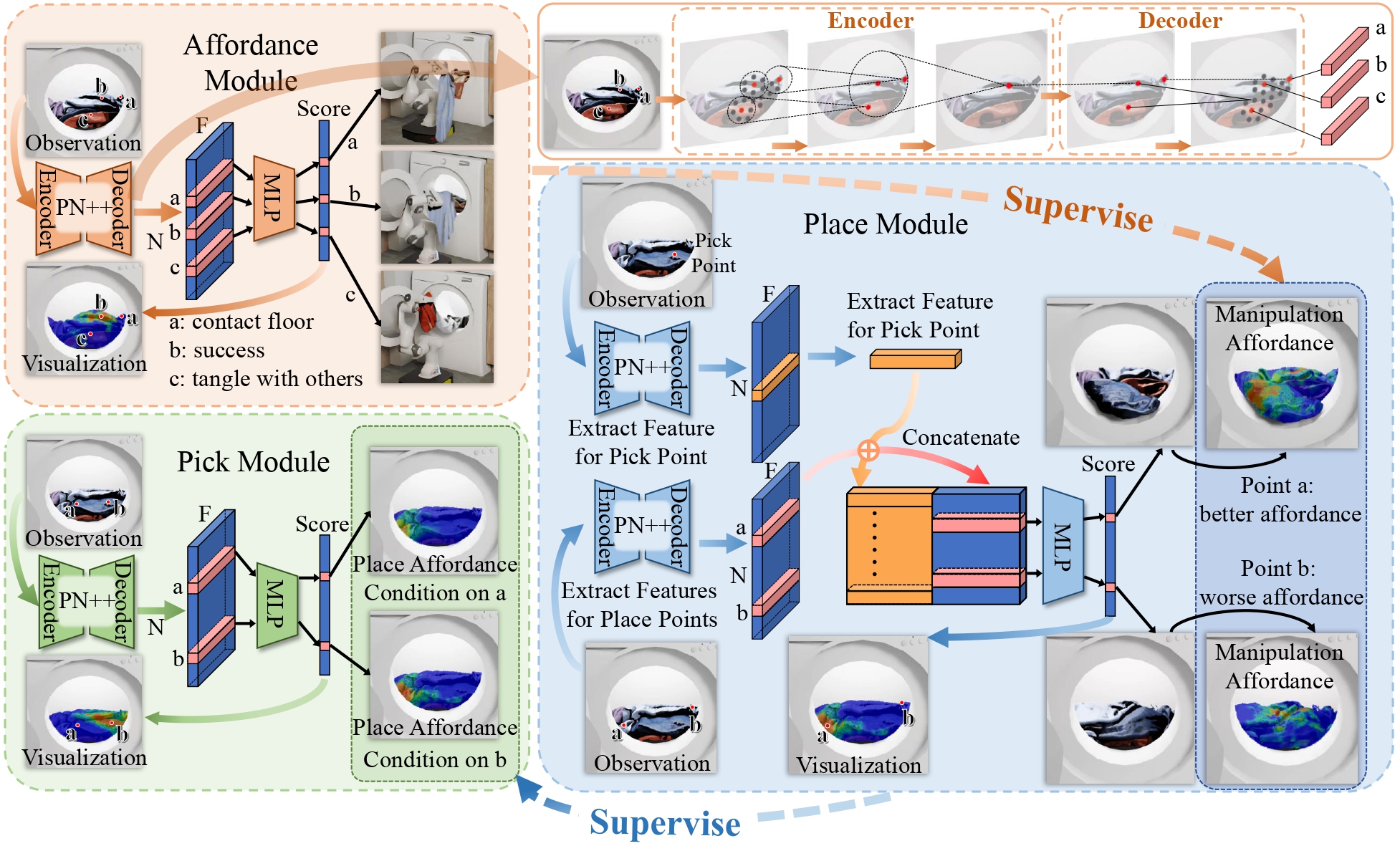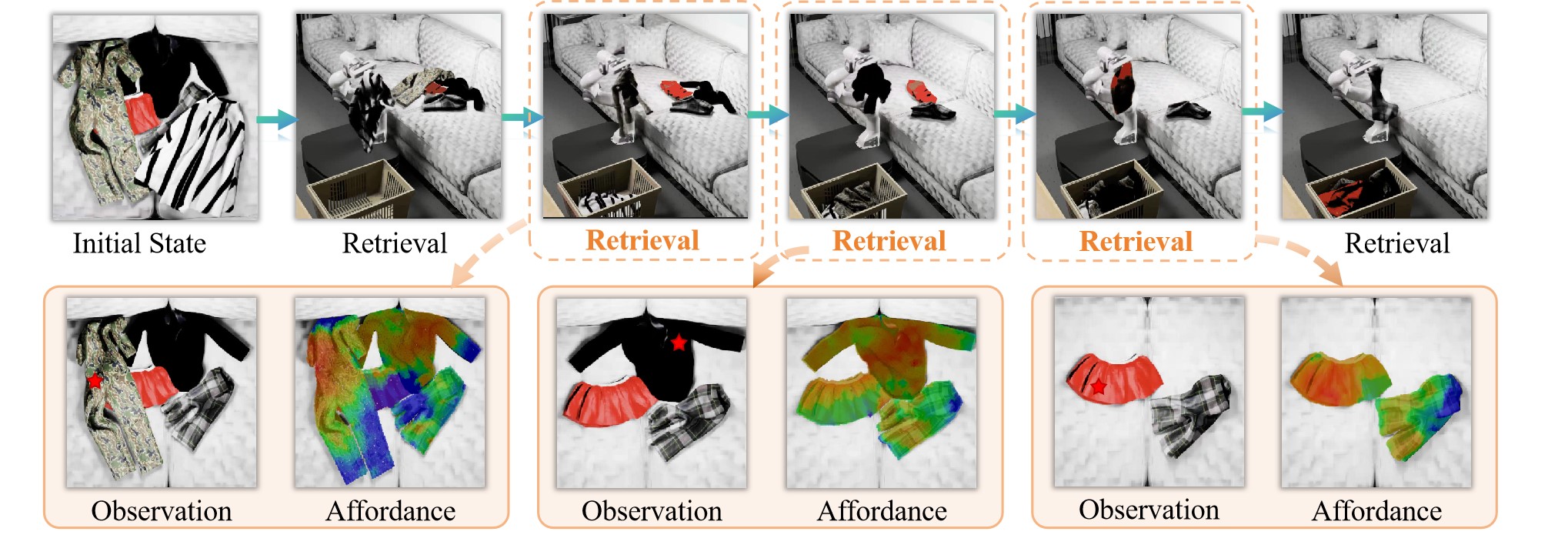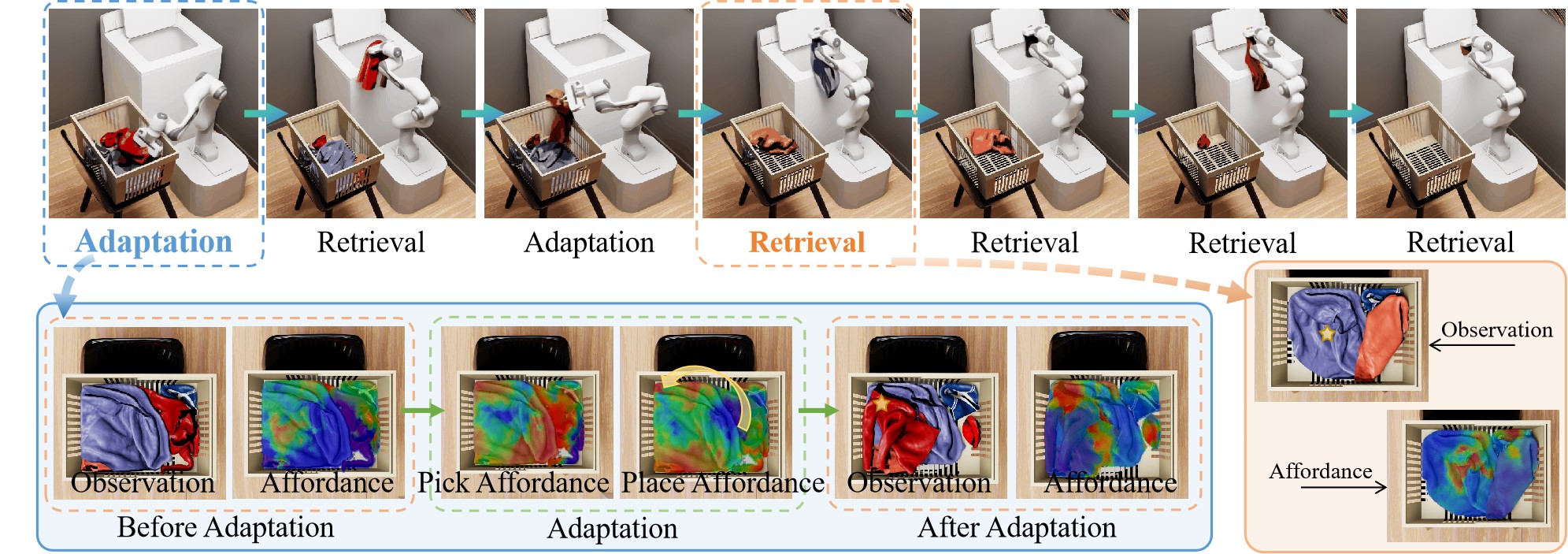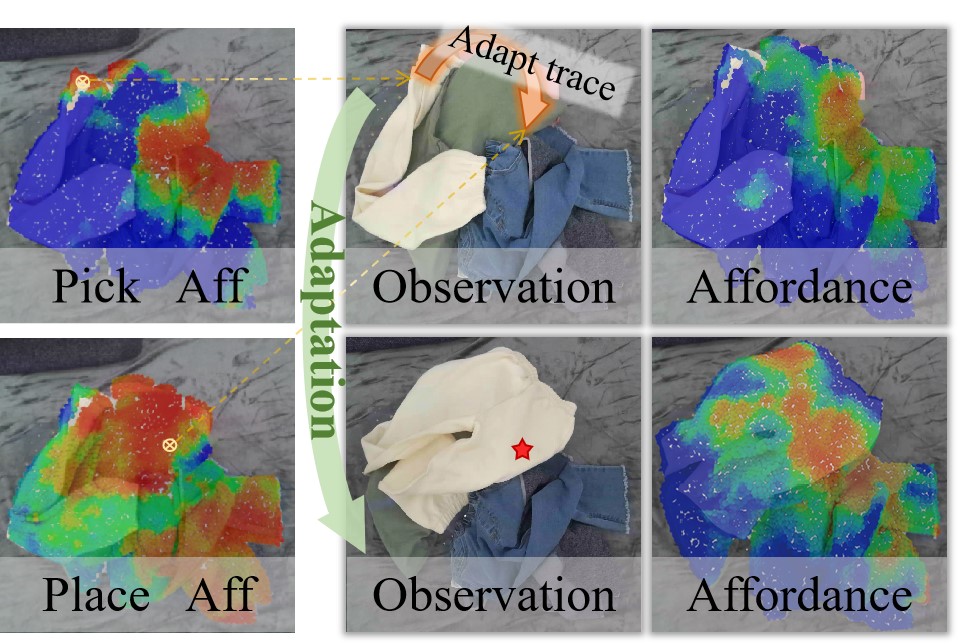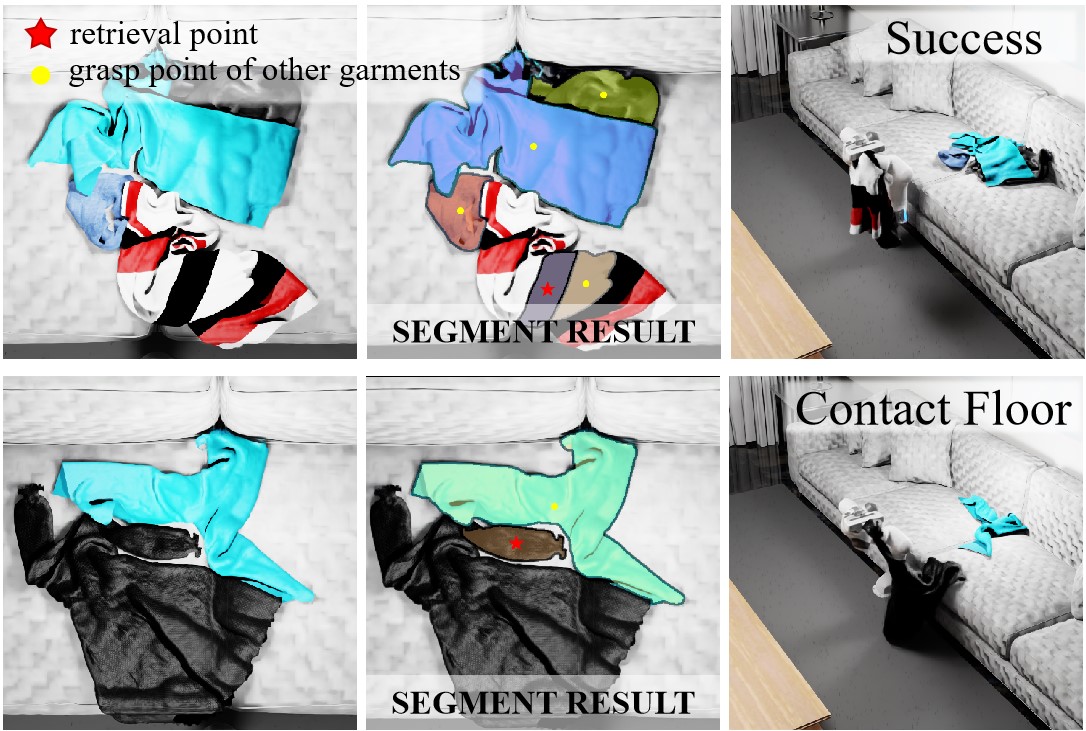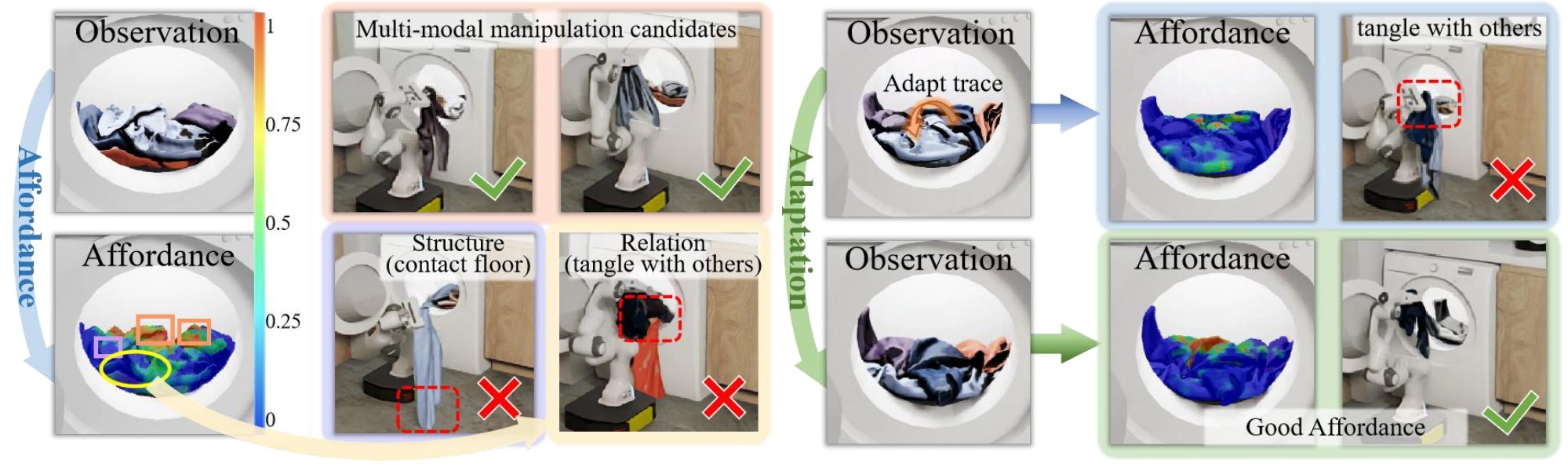
Point-Level Affordance for Cluttered Garments. A higher score denotes the higher actionability for downstream retrieval. Row 1: per-point affordance simultaneously reveals 2 garments suitable for retrieval. Row 2: it is aware of garment structures (grasping edges leads other parts contacting floor) and relations (retrieving one garment while dragging nearby entangled garments out), and thus avoids manipulating on points leading to such failures. Row 3 and 4: highly tangled garments may not have plausible manipulation points, affordance can guide reorganizing the scene, and thus garments plausible for manipulation will exist.